James Dargan

Aspiring Data Scientist
Seattle, WA
Python, SQL, R
Actively searching 

Pandas, BeautifulSoup, Requests, Plotly, Dash, nltk, Sklearn, Keras
Regression, PCA, Time Series, Trees, RFs, SVMs, Boosting, Neural Networks
MNIST Digit Classification (Repo)
Project Description:
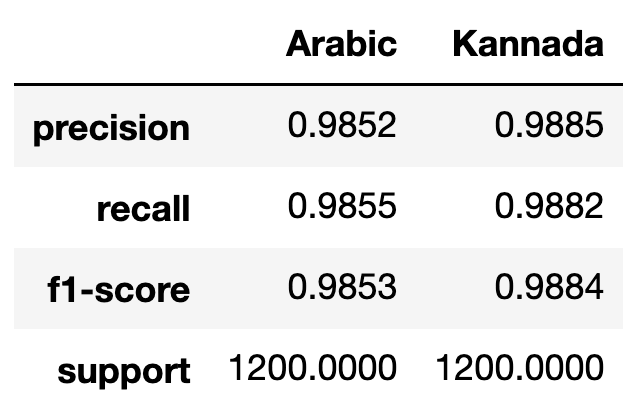
I combine the Arabic handwritten digits data with Kannada handwritten digits hosted on Kaggle to double the number of categories to predict. I then step-by-step test and optimize each layer component of a CNN architecture. My final model predicts all 20 digits with 98.692% test accuracy. I then explore errors introduced by confusion of digits from different languages. NB
Optimize Convolution Filter Count at 32-64

Determine Sufficient Dense Layer Size of 128
Optimize Dropout at 30% at each Layer
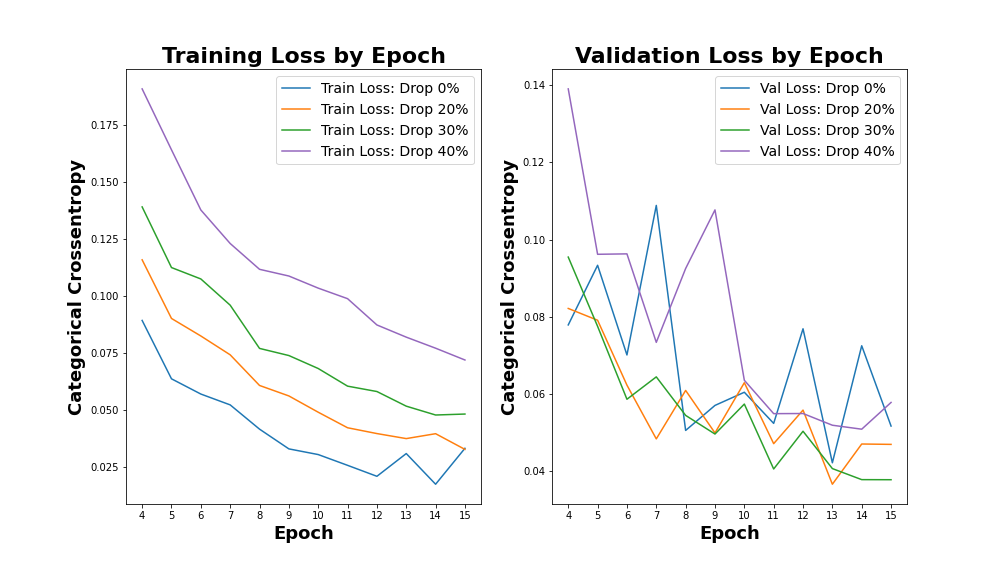
Insight 1: Stacking convolution layers and utilizing convolution with stride in place of max pooling do not improve performance. Traditional single-layer convolution of appropriate size with a MaxPooling layer performs sufficiently well to prefer for reduced complexity.
Insight 2: Of all test prediction errors, 28% derive from confusion across language. For example, the single greatest error in classifying Arabic digits came from confusion with the Kannada 0, with a total of 19 false predictions from the test data. Similarly, the non-loop style Arabic 2 was often confused with Kannada 7, illustrated below.

Insight 3: Despite visual similarity of curves in the Kannada digits, my CNN performs better on Kannada digits than Arabic digits, as measured by Precision, Recall, and Accuracy.